| Home » Articles » Հոդվածներ |
In statistics, regression analysis is a statistical process for estimating the relationships among variables. It includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables (or 'predictors'). More specifically, regression analysis helps one understand how the typical value of the dependent variable (or 'criterion variable') changes when any one of the independent variables is varied, while the other independent variables are held fixed. Most commonly, regression analysis estimates the conditional expectation of the dependent variable given the independent variables – that is, the average value of the dependent variable when the independent variables are fixed. Less commonly, the focus is on a quantile, or other location parameter of the conditional distribution of the dependent variable given the independent variables. In all cases, the estimation target is a function of the independent variables called the regression function. In regression analysis, it is also of interest to characterize the variation of the dependent variable around the regression function which can be described by a probability distribution. Regression analysis is widely used for prediction and forecasting, where its use has substantial overlap with the field of machine learning. Regression analysis is also used to understand which among the independent variables are related to the dependent variable, and to explore the forms of these relationships. In restricted circumstances, regression analysis can be used to infer causal relationships between the independent and dependent variables. However this can lead to illusions or false relationships, so caution is advisable;[1] for example, correlation does not imply causation. Many techniques for carrying out regression analysis have been developed. Familiar methods such as linear regression and ordinary least squares regression areparametric, in that the regression function is defined in terms of a finite number of unknown parameters that are estimated from the data. Nonparametric regressionrefers to techniques that allow the regression function to lie in a specified set of functions, which may be infinite-dimensional. The performance of regression analysis methods in practice depends on the form of the data generating process, and how it relates to the regression approach being used. Since the true form of the data-generating process is generally not known, regression analysis often depends to some extent on making assumptions about this process. These assumptions are sometimes testable if a sufficient quantity of data is available. Regression models for prediction are often useful even when the assumptions are moderately violated, although they may not perform optimally. However, in many applications, especially with small effects or questions of causality based on observational data, regression methods can give misleading results. In a narrower sense, regression may refer specifically to the estimation of continuous response variables, as opposed to the discrete response variables used in classification. The case of a continuous output variable may be more specifically referred to as metric regression to distinguish it from related problems. Regression modelsRegression models involve the following variables:
In various fields of application, different terminologies are used in place of dependent and independent variables. A regression model relates Y to a function of X and β. The approximation is usually formalized as E(Y | X) = f(X, β). To carry out regression analysis, the form of the function f must be specified. Sometimes the form of this function is based on knowledge about the relationship between Y and X that does not rely on the data. If no such knowledge is available, a flexible or convenient form for f is chosen. Assume now that the vector of unknown parameters β is of length k. In order to perform a regression analysis the user must provide information about the dependent variable Y:
In the last case, the regression analysis provides the tools for:
Necessary number of independent measurementsConsider a regression model which has three unknown parameters, β0, β1, and β2. Suppose an experimenter performs 10 measurements all at exactly the same value of independent variable vector X (which contains the independent variables X1, X2, and X3). In this case, regression analysis fails to give a unique set of estimated values for the three unknown parameters; the experimenter did not provide enough information. The best one can do is to estimate the average value and the standard deviation of the dependent variable Y. Similarly, measuring at two different values of X would give enough data for a regression with two unknowns, but not for three or more unknowns. If the experimenter had performed measurements at three different values of the independent variable vector X, then regression analysis would provide a unique set of estimates for the three unknown parameters inβ. In the case of general linear regression, the above statement is equivalent to the requirement that the matrix XTX is invertible. Statistical assumptions[edit]When the number of measurements, N, is larger than the number of unknown parameters, k, and the measurement errors εi are normally distributed then the excess of information contained in (N − k) measurements is used to make statistical predictions about the unknown parameters. This excess of information is referred to as the degrees of freedom of the regression. Underlying assumptions Classical assumptions for regression analysis include:
These are sufficient conditions for the least-squares estimator to possess desirable properties; in particular, these assumptions imply that the parameter estimates will be unbiased, consistent, and efficient in the class of linear unbiased estimators. It is important to note that actual data rarely satisfies the assumptions. That is, the method is used even though the assumptions are not true. Variation from the assumptions can sometimes be used as a measure of how far the model is from being useful. Many of these assumptions may be relaxed in more advanced treatments. Reports of statistical analyses usually include analyses of tests on the sample data and methodology for the fit and usefulness of the model. Assumptions include the geometrical support of the variables. Independent and dependent variables often refer to values measured at point locations. There may be spatial trends and spatial autocorrelation in the variables that violate statistical assumptions of regression. Geographic weighted regression is one technique to deal with such data. Also, variables may include values aggregated by areas. With aggregated data the modifiable areal unit problem can cause extreme variation in regression parameters. When analyzing data aggregated by political boundaries, postal codes or census areas results may be very distinct with a different choice of units. Linear regressionIn linear regression, the model specification is that the dependent variable,
In multiple linear regression, there are several independent variables or functions of independent variables. Adding a term in xi2 to the preceding regression gives:
This is still linear regression; although the expression on the right hand side is quadratic in the independent variable In both cases, Returning our attention to the straight line case: Given a random sample from the population, we estimate the population parameters and obtain the sample linear regression model: The residual, Minimization of this function results in a set of normal equations, a set of simultaneous linear equations in the parameters, which are solved to yield the parameter estimators, In the case of simple regression, the formulas for the least squares estimates are where Under the assumption that the population error term has a constant variance, the estimate of that variance is given by: This is called the mean square error (MSE) of the regression. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n-p) for p regressors or (n-p-1) if an intercept is used.In this case, p=1 so the denominator is n-2. The standard errors of the parameter estimates are given by Under the further assumption that the population error term is normally distributed, the researcher can use these estimated standard errors to create confidence intervals and conduct hypothesis tests about the population parameters. General linear modelIn the more general multiple regression model, there are p independent variables: where xij is the ith observation on the jth independent variable, and where the first independent variable takes the value 1 for all i (so The least squares parameter estimates are obtained from p normal equations. The residual can be written as The normal equations are In matrix notation, the normal equations are written as where the ij element of X is xij, the i element of the column vector Y is yi, and the j element of DiagnosticsOnce a regression model has been constructed, it may be important to confirm the goodness of fit of the model and the statistical significance of the estimated parameters. Commonly used checks of goodness of fit include the R-squared, analyses of the pattern of residuals and hypothesis testing. Statistical significance can be checked by an F-test of the overall fit, followed by t-tests of individual parameters. Interpretations of these diagnostic tests rest heavily on the model assumptions. Although examination of the residuals can be used to invalidate a model, the results of a t-test or F-test are sometimes more difficult to interpret if the model's assumptions are violated. For example, if the error term does not have a normal distribution, in small samples the estimated parameters will not follow normal distributions and complicate inference. With relatively large samples, however, a central limit theorem can be invoked such that hypothesis testing may proceed using asymptotic approximations. "Limited dependent" variablesThe phrase "limited dependent" is used in econometric statistics for categorical and constrained variables. The response variable may be non-continuous ("limited" to lie on some subset of the real line). For binary (zero or one) variables, if analysis proceeds with least-squares linear regression, the model is called thelinear probability model. Nonlinear models for binary dependent variables include the probit and logit model. The multivariate probit model is a standard method of estimating a joint relationship between several binary dependent variables and some independent variables. For categorical variables with more than two values there is the multinomial logit. For ordinal variables with more than two values, there are the ordered logit and ordered probit models. Censored regression models may be used when the dependent variable is only sometimes observed, and Heckman correction type models may be used when the sample is not randomly selected from the population of interest. An alternative to such procedures is linear regression based on polychoric correlation (or polyserial correlations) between the categorical variables. Such procedures differ in the assumptions made about the distribution of the variables in the population. If the variable is positive with low values and represents the repetition of the occurrence of an event, then count models like thePoisson regression or the negative binomial model may be used instead. Interpolation and extrapolationRegression models predict a value of the Y variable given known values of the X variables. Prediction within the range of values in the dataset used for model-fitting is known informally as interpolation. Predictionoutside this range of the data is known as extrapolation. Performing extrapolation relies strongly on the regression assumptions. The further the extrapolation goes outside the data, the more room there is for the model to fail due to differences between the assumptions and the sample data or the true values. It is generally advised that when performing extrapolation, one should accompany the estimated value of the dependent variable with a prediction interval that represents the uncertainty. Such intervals tend to expand rapidly as the values of the independent variable(s) moved outside the range covered by the observed data. For such reasons and others, some tend to say that it might be unwise to undertake extrapolation. However, this does not cover the full set of modelling errors that may be being made: in particular, the assumption of a particular form for the relation between Y and X. A properly conducted regression analysis will include an assessment of how well the assumed form is matched by the observed data, but it can only do so within the range of values of the independent variables actually available. This means that any extrapolation is particularly reliant on the assumptions being made about the structural form of the regression relationship. Best-practice advice here is that a linear-in-variables and linear-in-parameters relationship should not be chosen simply for computational convenience, but that all available knowledge should be deployed in constructing a regression model. If this knowledge includes the fact that the dependent variable cannot go outside a certain range of values, this can be made use of in selecting the model – even if the observed dataset has no values particularly near such bounds. The implications of this step of choosing an appropriate functional form for the regression can be great when extrapolation is considered. At a minimum, it can ensure that any extrapolation arising from a fitted model is "realistic" (or in accord with what is known). | |
| Views: 474 | |

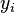 is a linear combination of the parameters (but need not be linear in the independent variables). For example, in simple linear regression for modeling
is a linear combination of the parameters (but need not be linear in the independent variables). For example, in simple linear regression for modeling  data points there is one independent variable:
data points there is one independent variable:  , and two parameters,
, and two parameters,  and
and  :
:


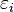 is an error term and the subscript
is an error term and the subscript  indexes a particular observation.
indexes a particular observation.
 , is the difference between the value of the dependent variable predicted by the model,
, is the difference between the value of the dependent variable predicted by the model,  , and the true value of the dependent variable,
, and the true value of the dependent variable, 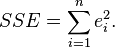
 .
.

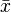 is the
is the  values and
values and 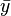 is the mean of the
is the mean of the  values.
values.

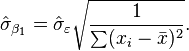
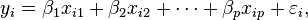



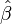 is
is  . Thus X is n×p, Y is n×1, and
. Thus X is n×p, Y is n×1, and 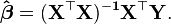
| Total comments: 0 | |